Master Slave Implementation


Master Slave/DB replication
As the name suggests, master-slave is a concept where there is one master and multiple slaves. The concept of master slave is also known as DB replication. Replication means having a copy or replicating something.
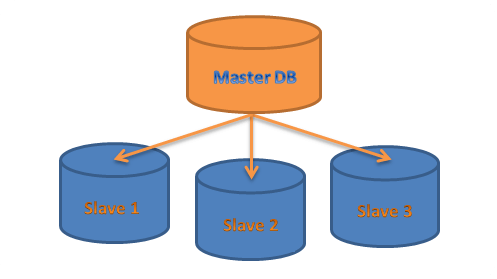
So, in the case of DB, let's say we have a complete DB and we will copy or replicate the same DB into another DB, which is known as the replica. The DB which has the source or which performs the write and read operations is known as the Master or Primary DB, and the replicas are known as Slaves or Secondary.
Why use it?
Let's say, for some reason, the master DB goes down. In that case, we can use the replica as we have the exact same data on the slaves. Also, in some scenarios, the slaves can become the master DB. So, in order to save the system from failure, we can use master-slave.
It help us to reduce the latency by keeping the data at multiple geographical location around the globe.
The primary database handles the all read and write operations whereas the secondary databases will handle only the read operations. It will help to increase the application performance and system scalability.
Types of Replication
Synchronous Replication: In this replication, any change on the primary DB is immediately propagated to all the other replicas. The update is complete only when all the replicas are updated . To proceed we need to wait for all the replicas to be updated which might be time consuming.
Also, in case any of the replica fails to update the whole update process fails.
Asynchronous Replication: In this replication, all the replicas are not updates at the same time. The update is considered complete when one database is updated, the operations are quicker than synchronous replications.
In case any of the replica fails to update the data then it leads to inconsistency in the database.